LOCATE: Localize and Transfer Object Parts for Weakly Supervised Affordance Grounding
CVPR 2023
Gen Li1 Varun Jampani2 Deqing Sun2 Laura Sevilla-Lara1
1University of Edinburgh 2Google Research
Abstract
Humans excel at acquiring knowledge through observation. For example, we can learn to use new tools by watching demonstrations. This skill is fundamental for intelligent systems to interact with the world. A key step to acquire this skill is to identify what part of the object affords each action, which is called affordance grounding. In this paper, we address this problem and propose a framework called LOCATE that can identify matching object parts across images, to transfer knowledge from images where an object is being used (exocentric images used for learning), to images where the object is inactive (egocentric ones used to test). To this end, we first find interaction areas and extract their feature embeddings. Then we learn to aggregate the embeddings into compact prototypes (human, object part, and background), and select the one representing the object part. Finally, we use the selected prototype to guide affordance grounding. We do this in a weakly supervised manner, learning only from image-level affordance and object labels. Extensive experiments demonstrate that our approach outperforms state-of-the-art methods by a large margin on both seen and unseen objects.

Pipeline
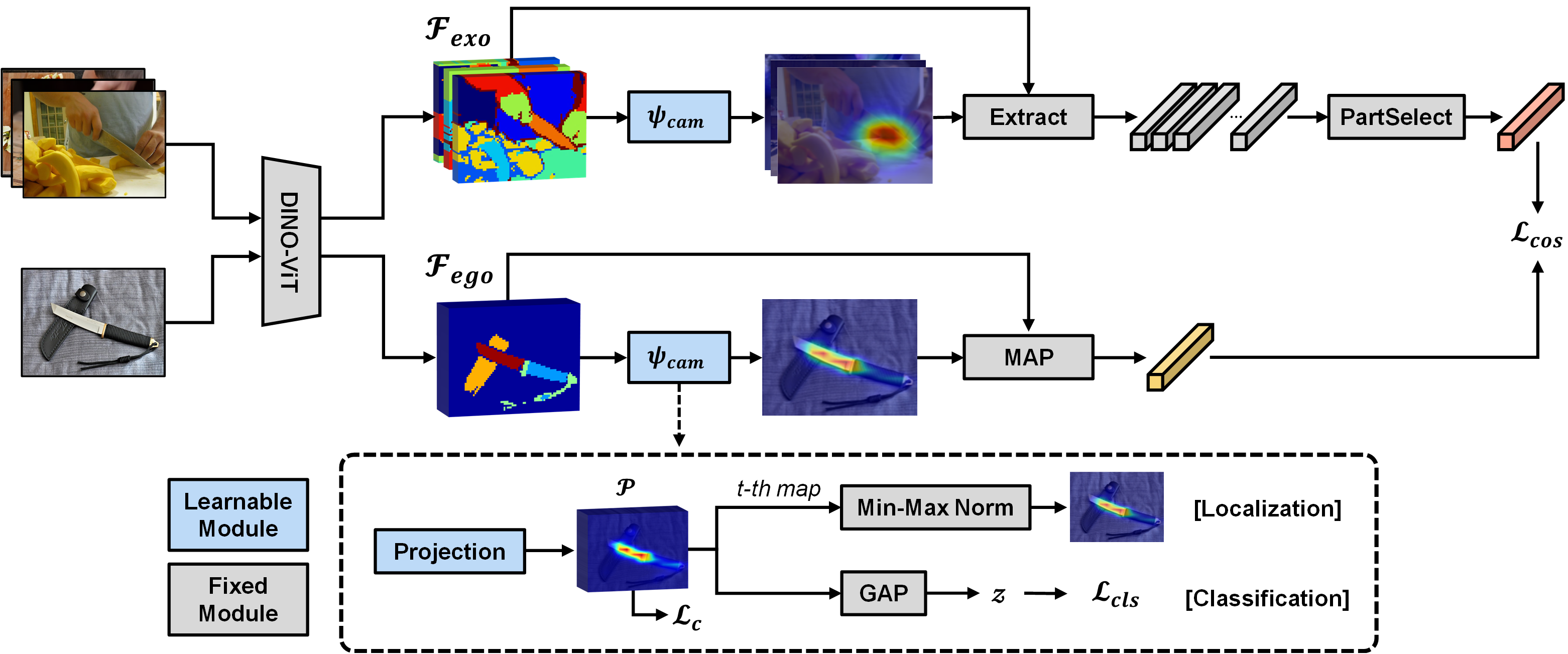
Video Summary
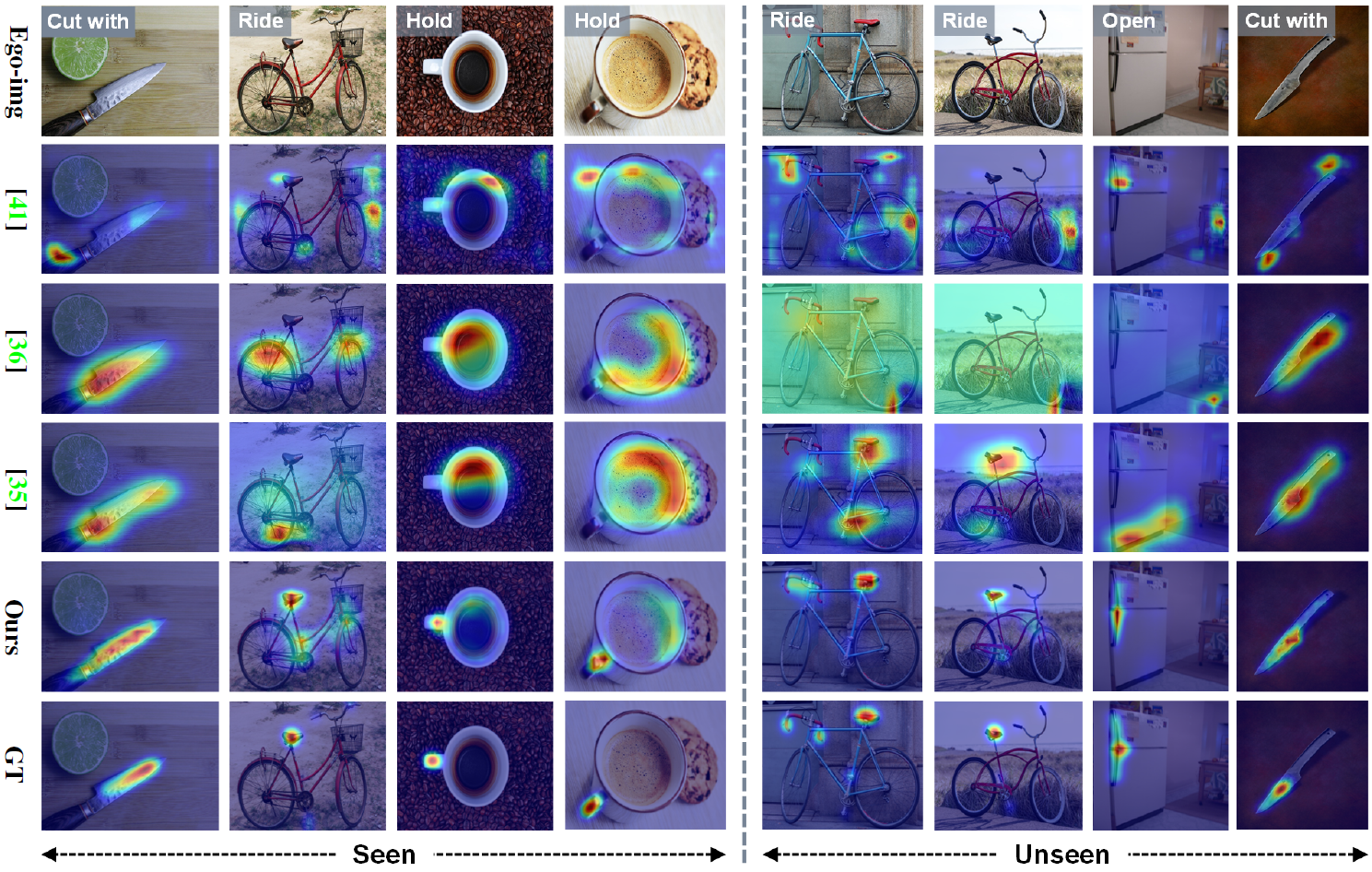
Qualitative Results
Citation
@inproceedings{li:locate:2023,
title = {LOCATE: Localize and Transfer Object Parts for Weakly Supervised Affordance Grounding},
author = {Li, Gen and Jampani, Varun and Sun, Deqing and Sevilla-Lara, Laura},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year={2023}
}