@inproceedings{evo1,title={Evo-1: Lightweight Vision-Language-Action Model with Preserved Semantic Alignment},author={Lin, Tao and Zhong, Yilei and Du, Yuxin and Zhang, Jingjing and Liu, Jiting and Chen, Yinxinyu and Gu, Encheng and Liu, Ziyan and Cai, Hongyi and Zou, Yanwen and Zou, Lixing and Zhou, Zhaoye and Li, Gen and Zhao, Bo},year={2026},booktitle={IEEE/CVF Conference on Computer Vision and Pattern Recognition},}
CVPR’26
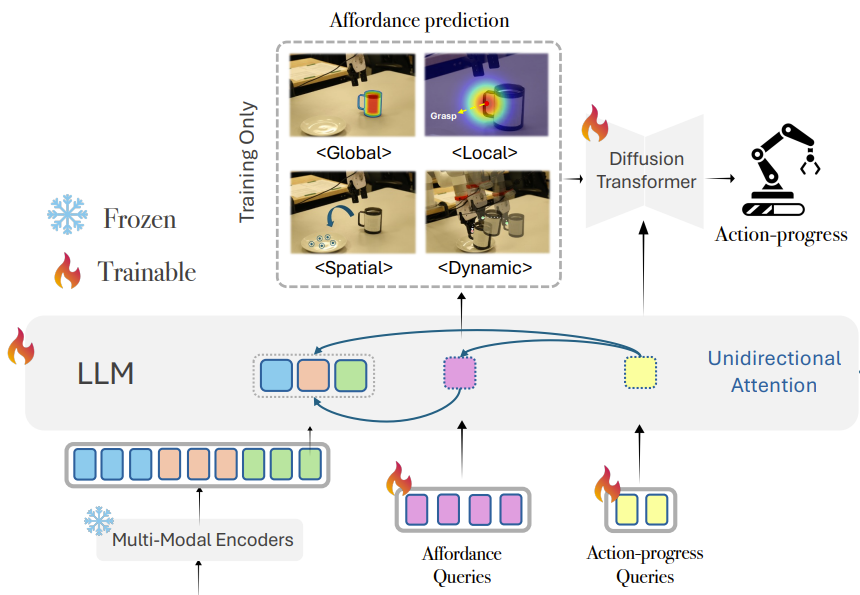
PALM: Progress-Aware Policy Learning via Affordance Reasoning for Long-Horizon Robotic Manipulation
Yuanzhe Liu, Jingyuan Zhu, Yuchen Mo, Gen Li, Xu Cao, and 7 more authors
In IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2026
@inproceedings{palm,title={PALM: Progress-Aware Policy Learning via Affordance Reasoning for Long-Horizon Robotic Manipulation},author={Liu, Yuanzhe and Zhu, Jingyuan and Mo, Yuchen and Li, Gen and Cao, Xu and Jin, Jin and Shen, Yifan and Li, Zhengyuan and Yu, Tianjiao and Yuan, Wenzhen and Ding, Fangqiang and Lourentzou, Ismini},year={2026},booktitle={IEEE/CVF Conference on Computer Vision and Pattern Recognition},}
AAAI’26
Mask2IV: Interaction-Centric Video Generation via Mask Trajectories
Gen Li, Bo Zhao, Jianfei Yang, and Laura Sevilla-Lara
In AAAI Conference on Artificial Intelligence, 2026
@inproceedings{Mask2IV,title={Mask2IV: Interaction-Centric Video Generation via Mask Trajectories},author={Li, Gen and Zhao, Bo and Yang, Jianfei and Sevilla-Lara, Laura},year={2026},booktitle={AAAI Conference on Artificial Intelligence},}
2025
ACM MM’25
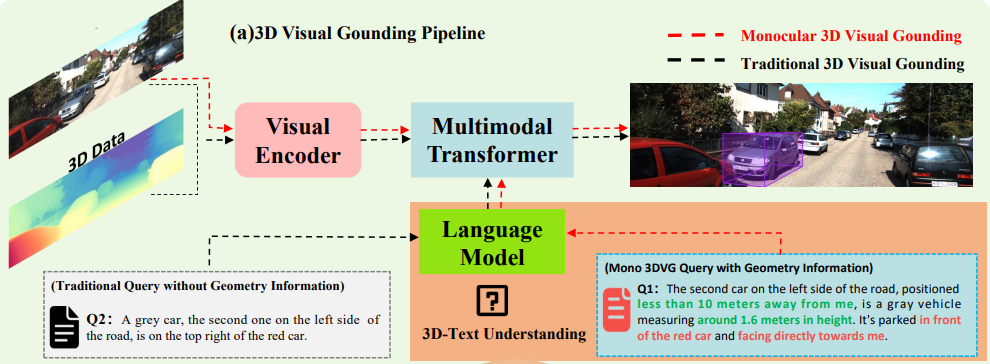
Dual Enhancement on 3D Vision-Language Perception for Monocular 3D Visual Grounding
Yuzhen Li, Min Liu, Yuan Bian, Xueping Wang, Zhaoyang Li, and 2 more authors
In Proceedings of the 33rd ACM International Conference on Multimedia, 2025
@inproceedings{li2025dual,title={Dual Enhancement on 3D Vision-Language Perception for Monocular 3D Visual Grounding},author={Li, Yuzhen and Liu, Min and Bian, Yuan and Wang, Xueping and Li, Zhaoyang and Li, Gen and Wang, Yaonan},booktitle={Proceedings of the 33rd ACM International Conference on Multimedia},year={2025},}
ICCV’25
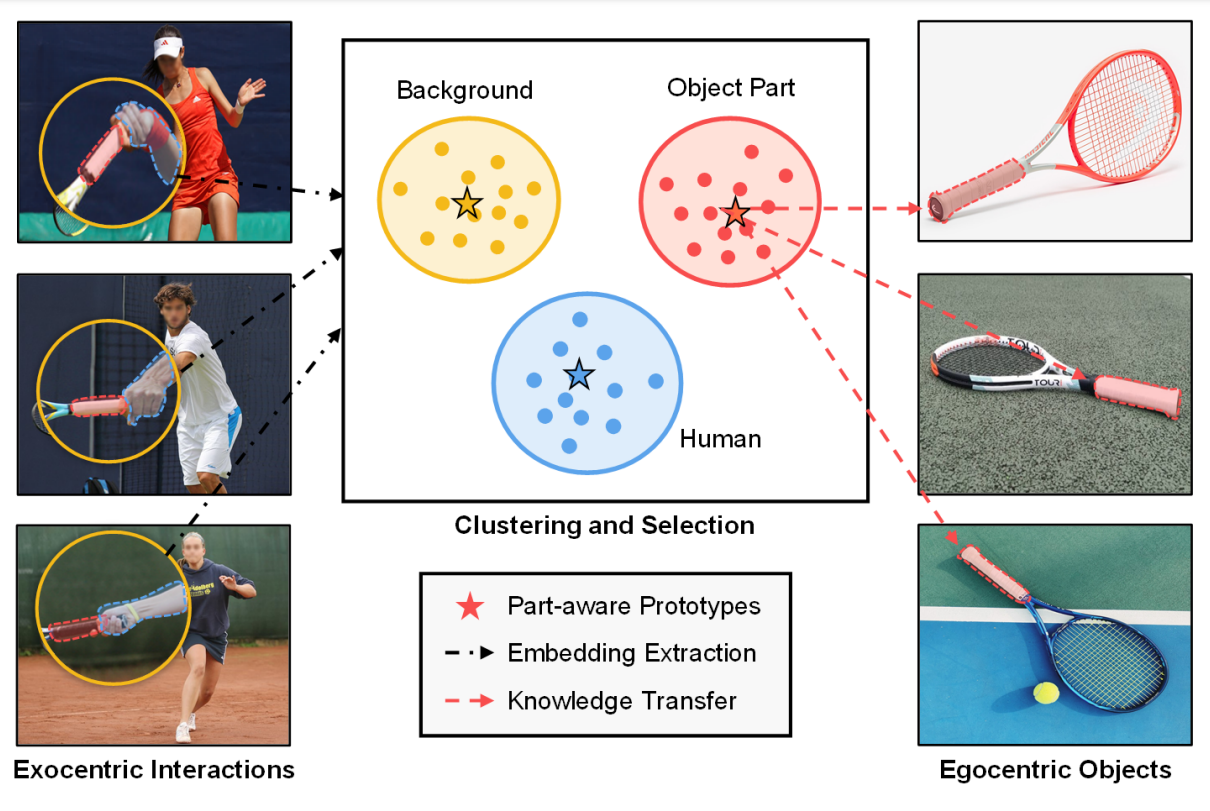
Learning Precise Affordances from Egocentric Videos for Robotic Manipulation
Gen Li, Nikolaos Tsagkas, Jifei Song, Ruaridh Mon-Williams, Sethu Vijayakumar, and 2 more authors
In IEEE/CVF International Conference on Computer Vision, 2025
@inproceedings{Aff-Grasp,title={Learning Precise Affordances from Egocentric Videos for Robotic Manipulation},author={Li, Gen and Tsagkas, Nikolaos and Song, Jifei and Mon-Williams, Ruaridh and Vijayakumar, Sethu and Shao, Kun and Sevilla-Lara, Laura},year={2025},booktitle={IEEE/CVF International Conference on Computer Vision},}
ICCV’25
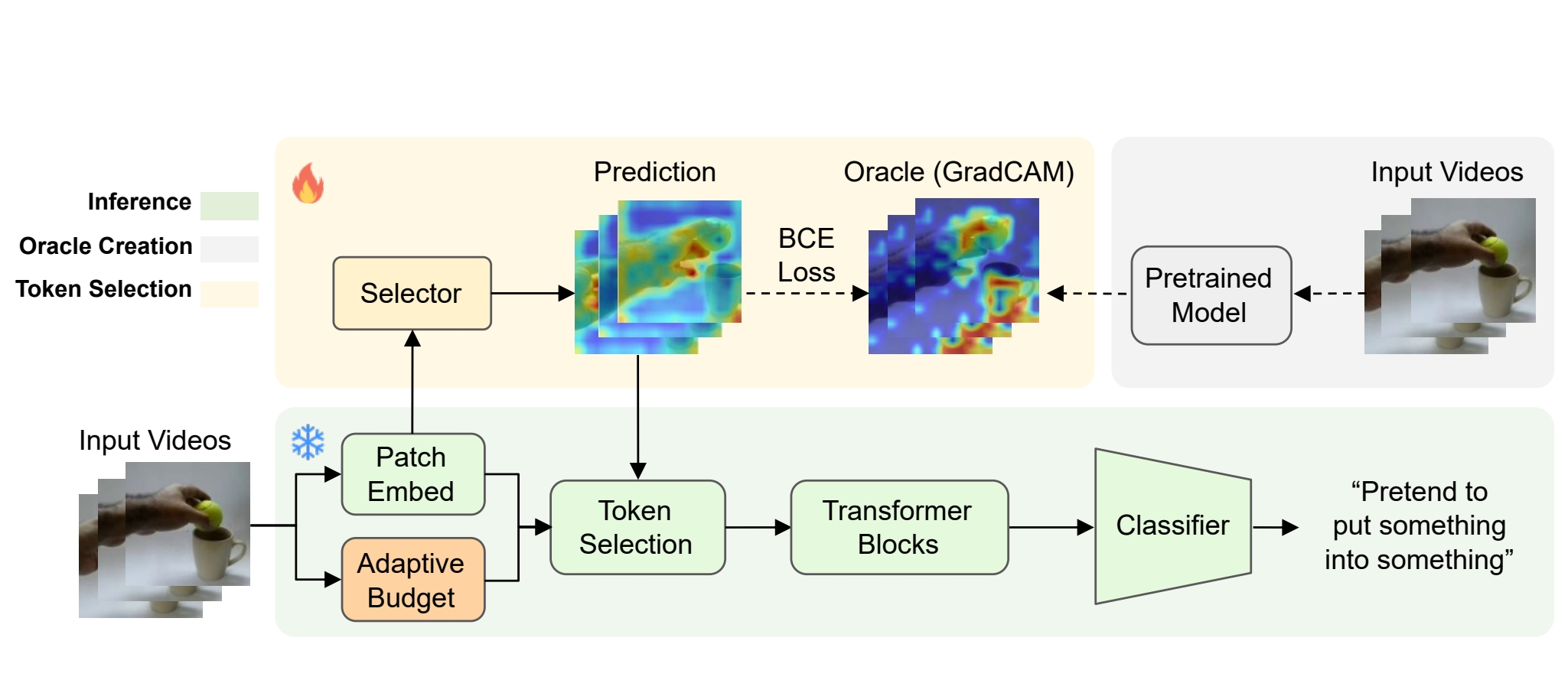
Principles of Visual Tokens for Efficient Video Understanding
Xinyue Hao, Gen Li, Shreyank N Gowda, Robert B Fisher, Jonathan Huang, and 2 more authors
In IEEE/CVF International Conference on Computer Vision, 2025
@inproceedings{hao2024principles,title={Principles of Visual Tokens for Efficient Video Understanding},author={Hao, Xinyue and Li, Gen and Gowda, Shreyank N and Fisher, Robert B and Huang, Jonathan and Arnab, Anurag and Sevilla-Lara, Laura},booktitle={IEEE/CVF International Conference on Computer Vision},year={2025},}
IROS’25
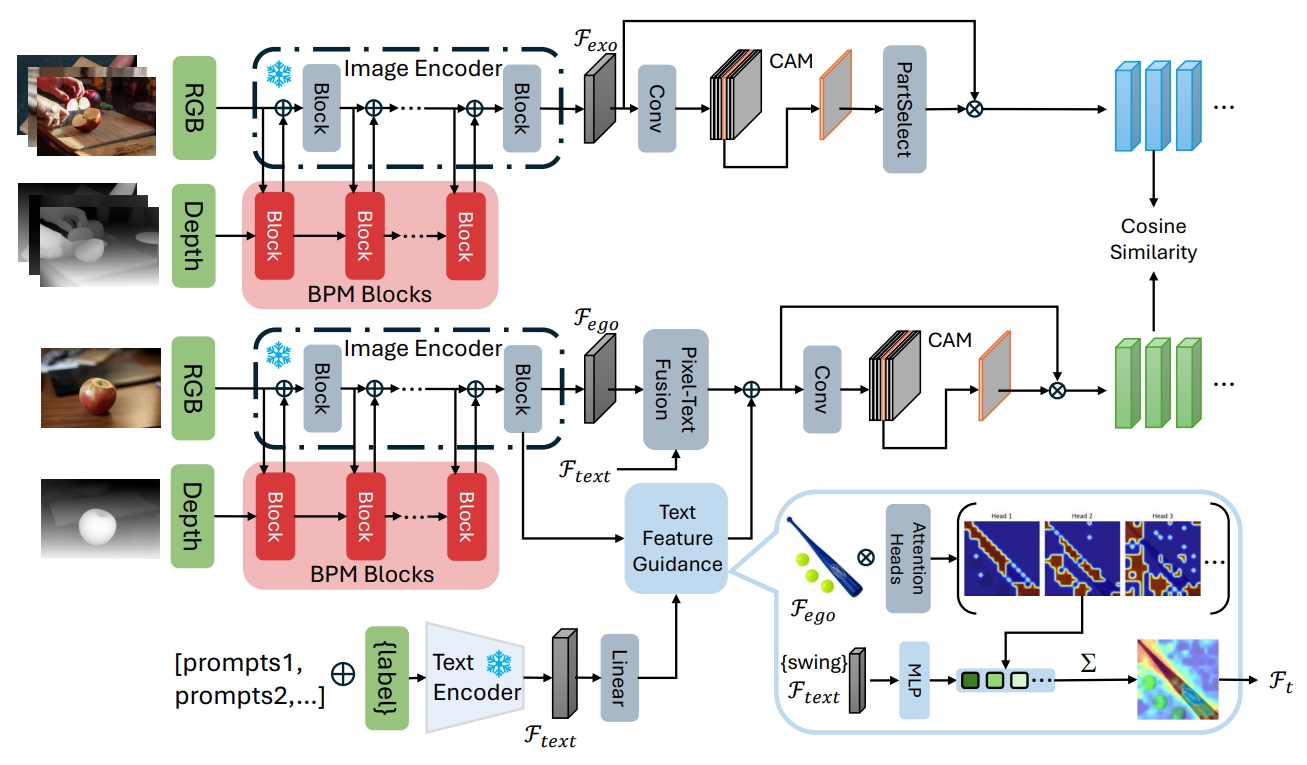
Resource-Efficient Affordance Grounding with Complementary Depth and Semantic Prompts
Yizhou Huang, Fan Yang, Guoliang Zhu, Gen Li, Hao Shi, and 4 more authors
In International Conference on Intelligent Robots and Systems, 2025
@inproceedings{huang2025resource,title={Resource-Efficient Affordance Grounding with Complementary Depth and Semantic Prompts},author={Huang, Yizhou and Yang, Fan and Zhu, Guoliang and Li, Gen and Shi, Hao and Zuo, Yukun and Chen, Wenrui and Li, Zhiyong and Yang, Kailun},booktitle={International Conference on Intelligent Robots and Systems},year={2025},}
@article{ELLMER,title={Embodied Large Language Models Enable Robots to Complete Complex Tasks in Unpredictable Environments},author={Mon-Williams, Ruaridh and Li, Gen and Long, Ran and Du, Wenqian and Lucas, Chris},journal={Nature Machine Intelligence},year={2025},}
2024
ECCVW’24
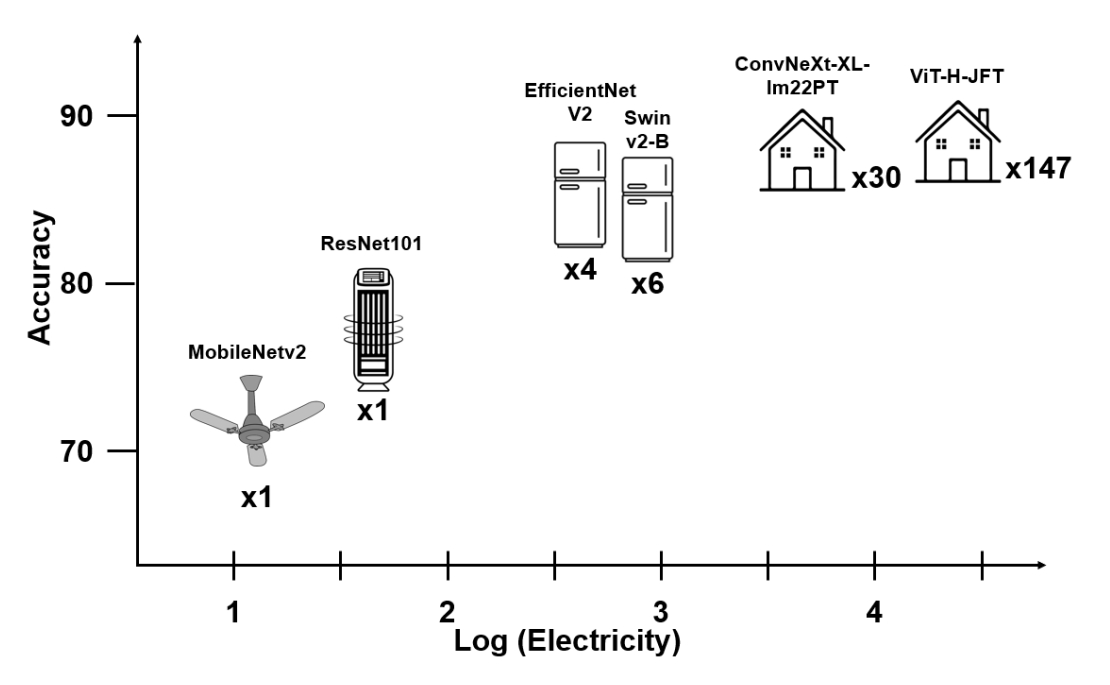
Watt for what: Rethinking deep learning’s energy-performance relationship
Shreyank N Gowda, Xinyue Hao, Gen Li, Shashank Narayana Gowda, Xiaobo Jin, and 1 more author
In European Conference on Computer Vision Workshop, 2024
@inproceedings{gowda2025watt,title={Watt for what: Rethinking deep learning’s energy-performance relationship},author={Gowda, Shreyank N and Hao, Xinyue and Li, Gen and Gowda, Shashank Narayana and Jin, Xiaobo and Sevilla-Lara, Laura},booktitle={European Conference on Computer Vision Workshop},pages={388--405},year={2024},organization={Springer},}
CVPR’24
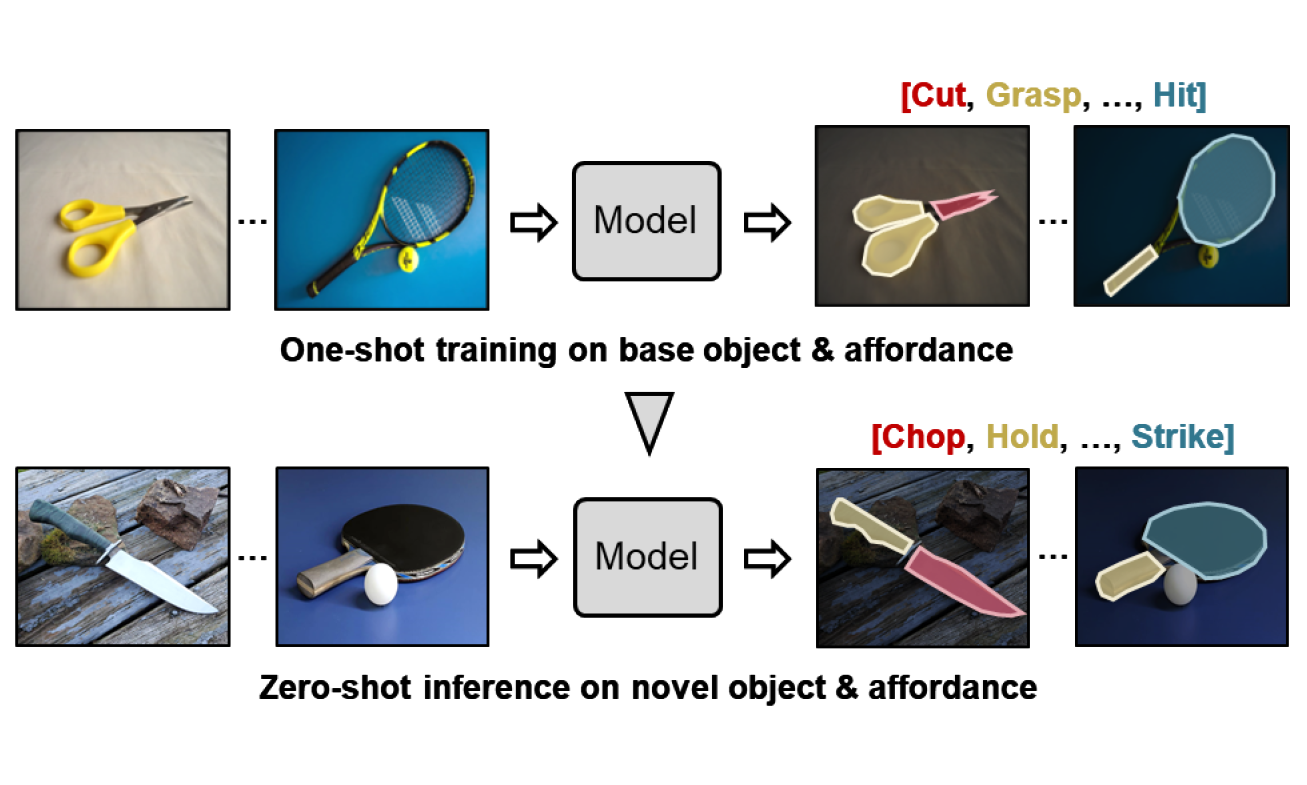
One-Shot Open Affordance Learning with Foundation Models
Gen Li, Deqing Sun, Laura Sevilla-Lara, and Varun Jampani
In IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024
@inproceedings{OOAL,title={One-Shot Open Affordance Learning with Foundation Models},author={Li, Gen and Sun, Deqing and Sevilla-Lara, Laura and Jampani, Varun},booktitle={IEEE/CVF Conference on Computer Vision and Pattern Recognition},year={2024},}
2023
IJCNN’23
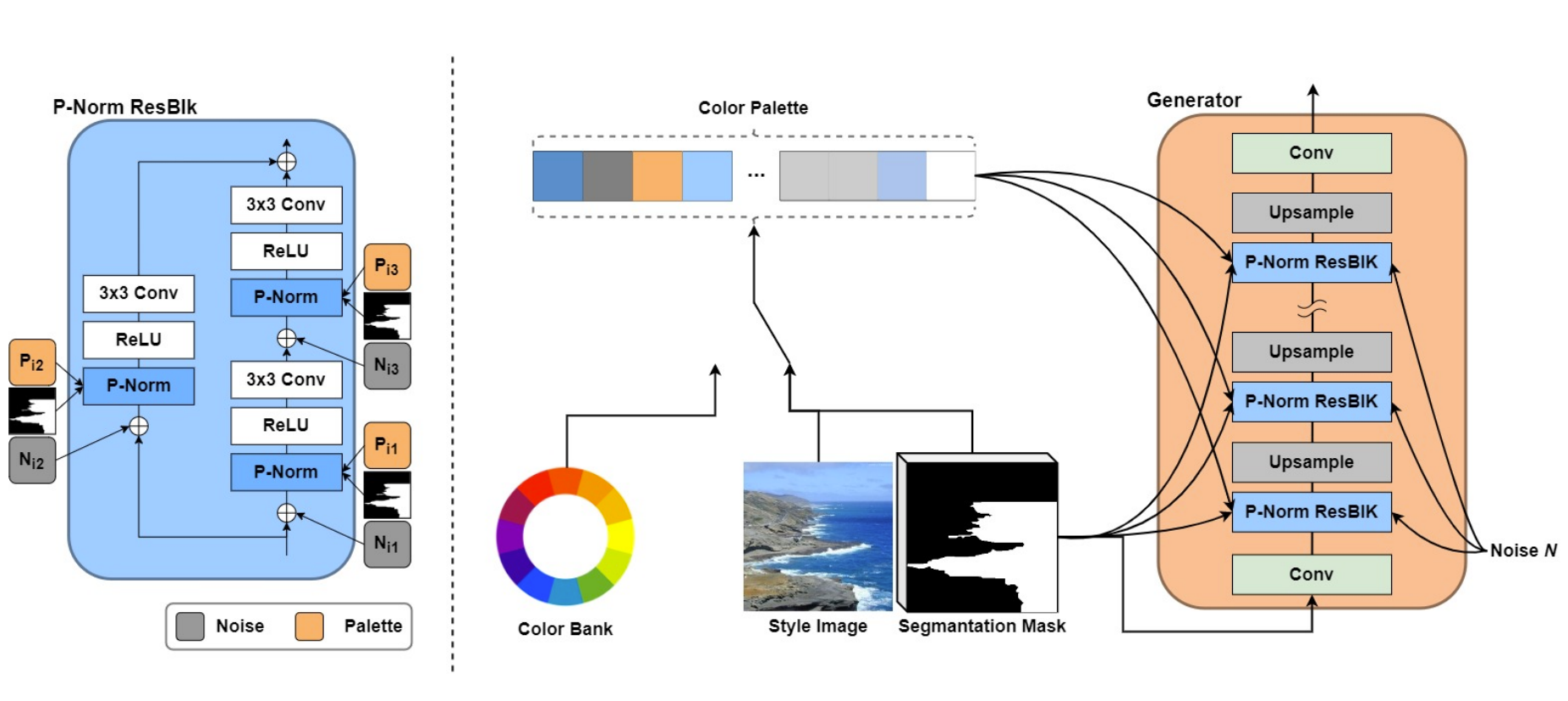
Referenceless User Controllable Semantic Image Synthesis
Jonghyun Kim, Gen Li, and Joongkyu Kim
In International Joint Conference on Neural Networks, 2023
@inproceedings{Refer,title={Referenceless User Controllable Semantic Image Synthesis},author={Kim, Jonghyun and Li, Gen and Kim, Joongkyu},booktitle={International Joint Conference on Neural Networks},year={2023},}
CVPR’23
LOCATE: Localize and Transfer Object Parts for Weakly Supervised Affordance Grounding
Gen Li, Varun Jampani, Deqing Sun, and Laura Sevilla-Lara
In IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023
@inproceedings{LOCATE,title={LOCATE: Localize and Transfer Object Parts for Weakly Supervised Affordance Grounding},author={Li, Gen and Jampani, Varun and Sun, Deqing and Sevilla-Lara, Laura},booktitle={IEEE/CVF Conference on Computer Vision and Pattern Recognition},year={2023},}
2021
CVPR’21
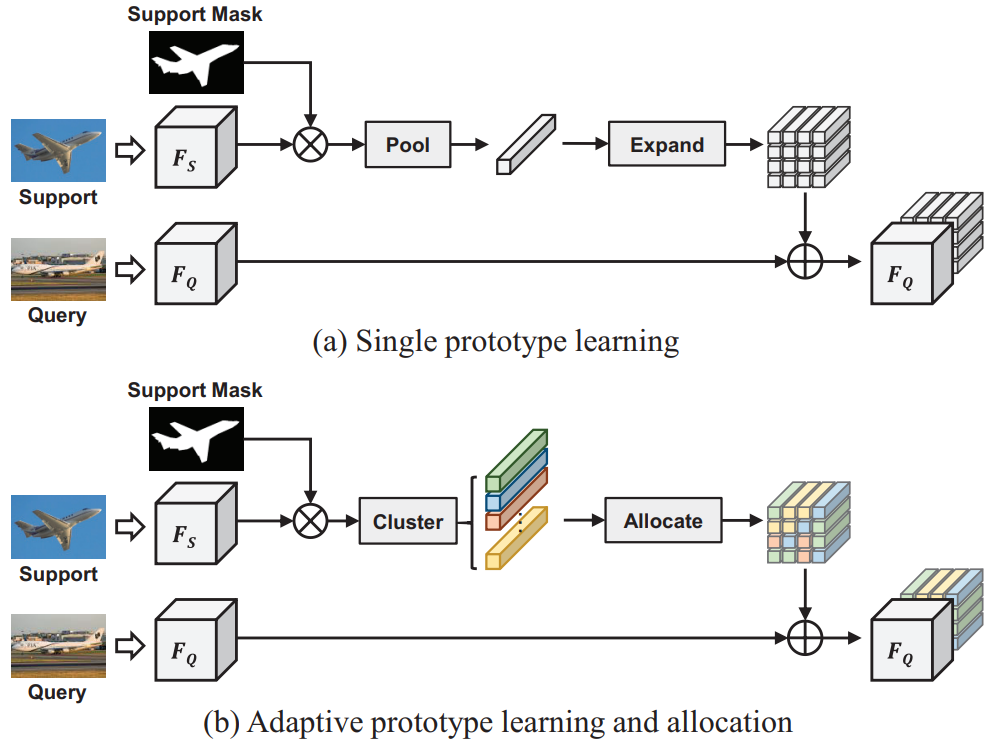
Adaptive Prototype Learning and Allocation for Few-Shot Segmentation
Gen Li, Varun Jampani, Laura Sevilla-Lara, Deqing Sun, Jonghyun Kim, and 1 more author
In IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021
@inproceedings{ASGNet,title={Adaptive Prototype Learning and Allocation for Few-Shot Segmentation},author={Li, Gen and Jampani, Varun and Sevilla-Lara, Laura and Sun, Deqing and Kim, Jonghyun and Kim, Joongkyu},booktitle={IEEE/CVF Conference on Computer Vision and Pattern Recognition},pages={8334--8343},year={2021},}
BMVC’21
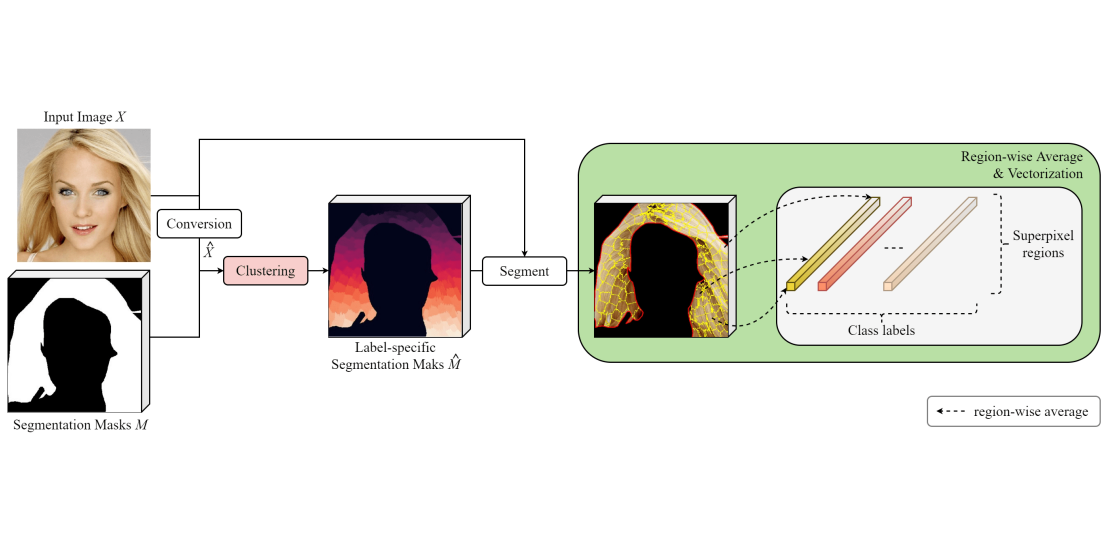
SuperStyleNet: Deep Image Synthesis with Superpixel Based Style Encoder
Jonghyun Kim, Gen Li, Cheolkon Jung, and Joongkyu Kim
@inproceedings{kim2021superstylenet,title={SuperStyleNet: Deep Image Synthesis with Superpixel Based Style Encoder},author={Kim, Jonghyun and Li, Gen and Jung, Cheolkon and Kim, Joongkyu},booktitle={British Machine Vision Conference},year={2021},}
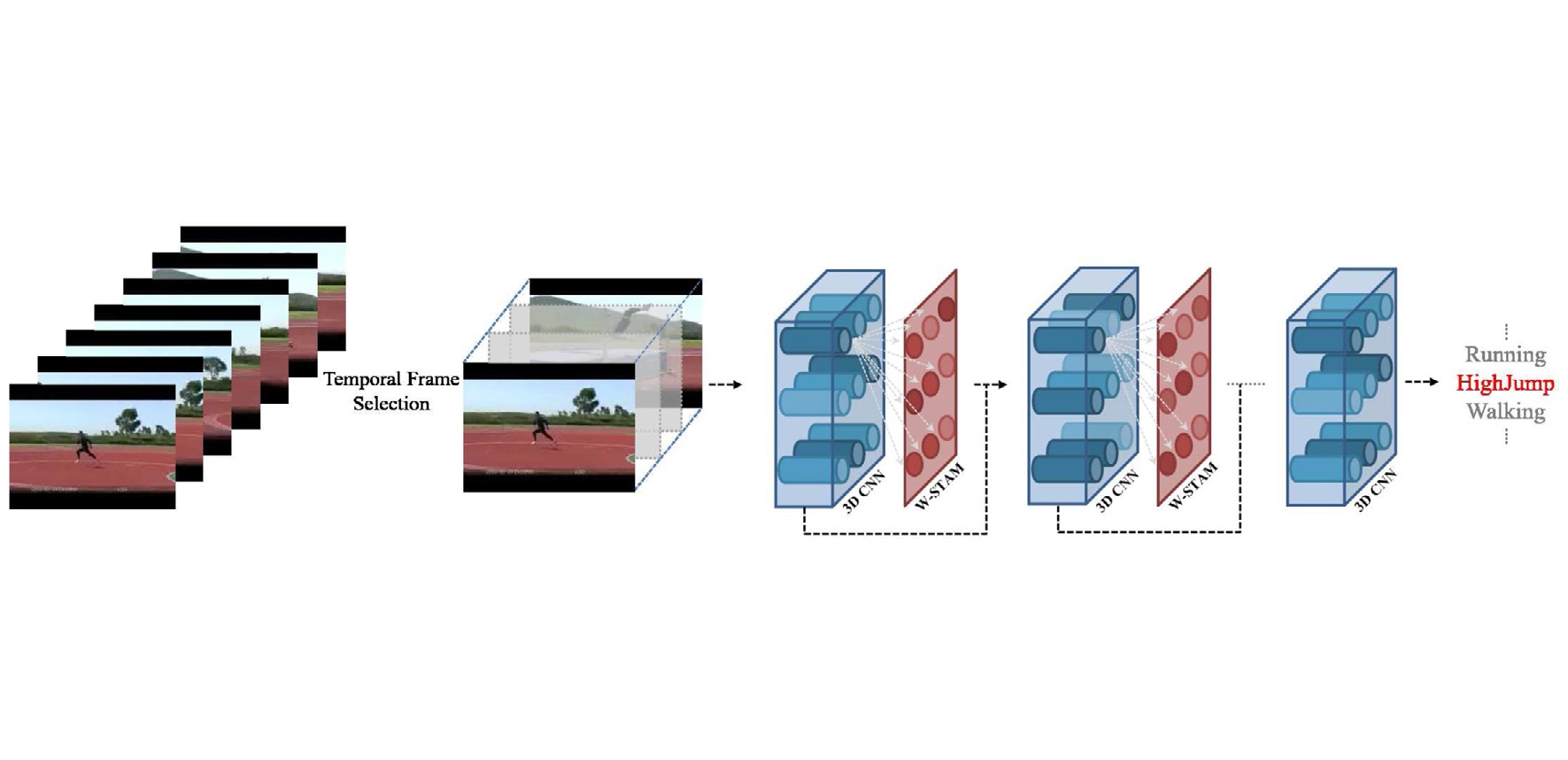
@article{KIM2021108068,title={Weakly-supervised temporal attention 3D network for human action recognition},journal={Pattern Recognition},volume={119},pages={108068},year={2021},issn={0031-3203},author={Kim, Jonghyun and Li, Gen and Yun, Inyong and Jung, Cheolkon and Kim, Joongkyu},keywords={Action recognition, Temporal attention, Convolutional neural network, Weakly-supervised learning, Video analysis, Video classification},}
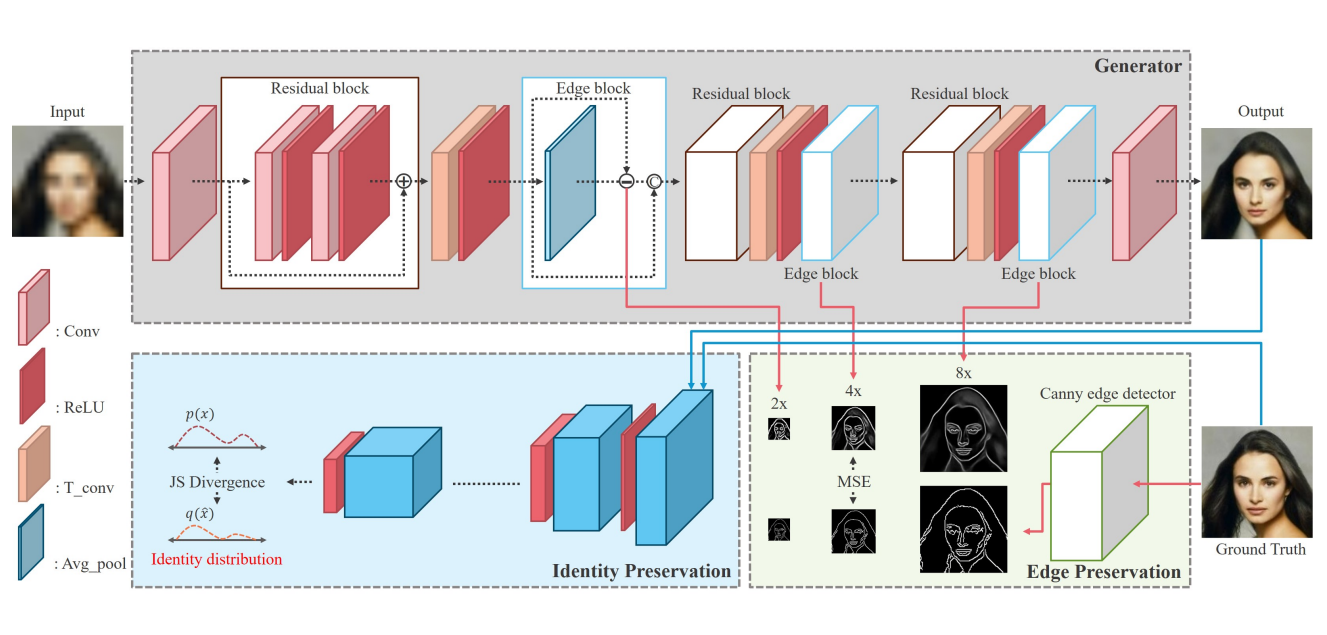
@article{KIM202111,title={Edge and identity preserving network for face super-resolution},journal={Neurocomputing},volume={446},pages={11-22},year={2021},issn={0925-2312},author={Kim, Jonghyun and Li, Gen and Yun, Inyong and Jung, Cheolkon and Kim, Joongkyu},keywords={Super-resolution, Face hallucination, Edge block, Identity loss, Image enhancement},}
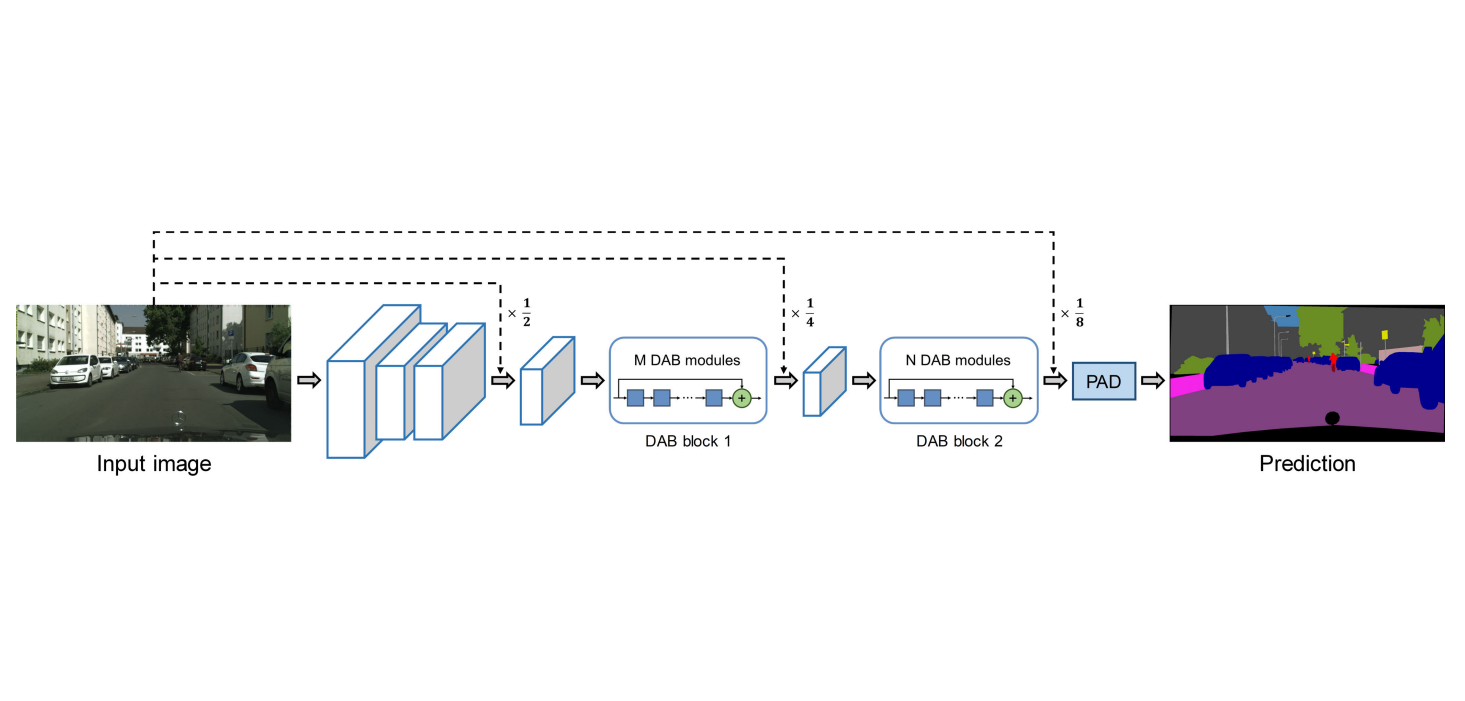
@article{dab_access,title={Depth-Wise Asymmetric Bottleneck With Point-Wise Aggregation Decoder for Real-Time Semantic Segmentation in Urban Scenes},author={Li, Gen and Jiang, Shenlu and Yun, Inyong and Kim, Jonghyun and Kim, Joongkyu},journal={IEEE Access},year={2020},volume={8},number={},pages={27495-27506},}
2019
BMVC’19
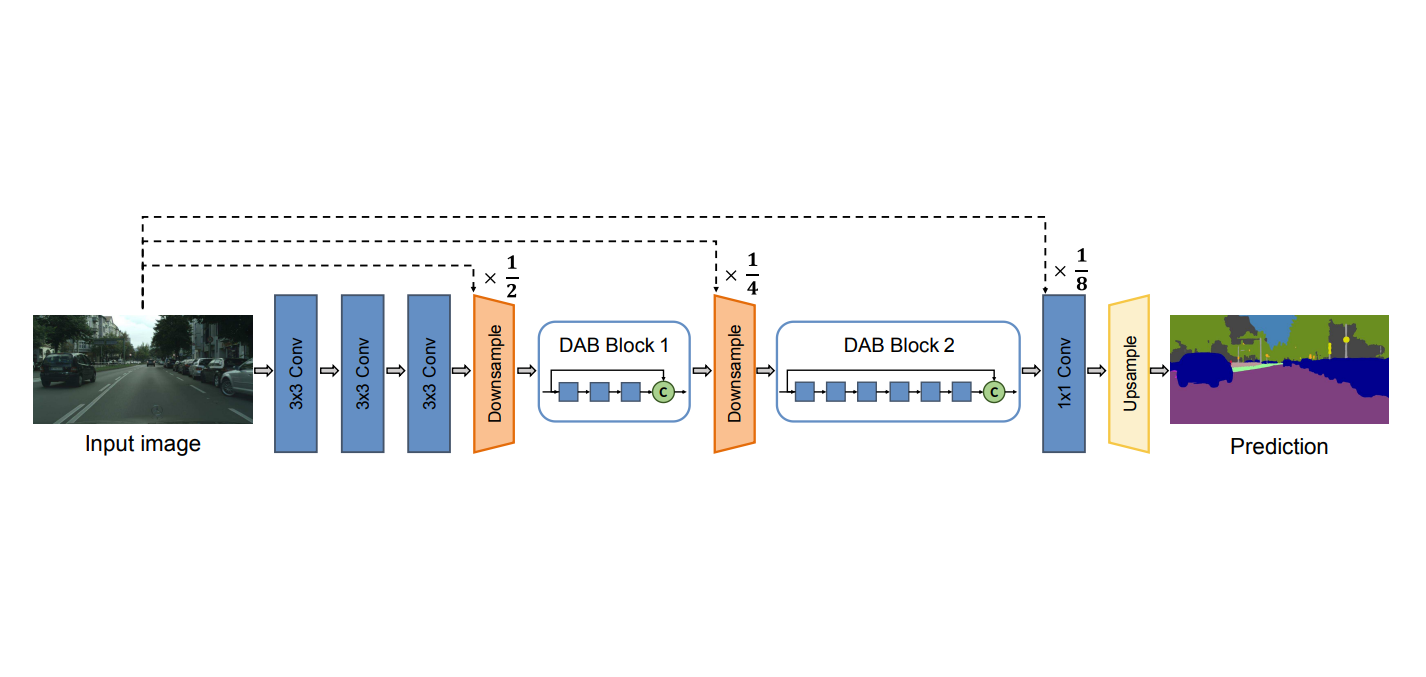
DABNet: Depth-wise asymmetric bottleneck for real-time semantic segmentation
@inproceedings{DABNet,title={DABNet: Depth-wise asymmetric bottleneck for real-time semantic segmentation},author={Li, Gen and Kim, Joongkyu},booktitle={British Machine Vision Conference},year={2019},}